

作者:王琛(中國(guó)科學(xué)院計(jì)算技術(shù)研究所在讀博士)
監(jiān)制:中國(guó)科普博覽
編者按:為展現(xiàn)智能科技動(dòng)態(tài),科普中國(guó)前沿科技項(xiàng)目推出“人工智能”系列文章,一窺人工智能前沿進(jìn)展,回應(yīng)種種關(guān)切與好奇。讓我們共同探究,迎接智能時(shí)代。
最近,DeepSeek作為AI界一位“新頂流”,憑借強(qiáng)大的功能在社交媒體上引發(fā)熱議。有人說它是未來的生產(chǎn)力工具,有人好奇它能為生活帶來哪些改變,也有人擔(dān)心它會(huì)搶走自己的飯碗……
為了讓大家更加了解這個(gè)備受關(guān)注的智能幫手,我們邀請(qǐng)了中國(guó)科學(xué)院計(jì)算技術(shù)研究所在讀博士王琛,用10個(gè)問題全面解答關(guān)于DeepSeek的核心原理、使用技巧以及未來趨勢(shì)等疑問。無論是AI小白還是科技達(dá)人,這篇文章都能為你答疑解惑!讓我們一起看看,這個(gè)“智能幫手”能否成為我們生活中的真正伙伴吧!
- DeepSeek在春節(jié)期間受到全球的關(guān)注,現(xiàn)在許多平臺(tái)都表示已經(jīng)接入DeepSeek大模型,它究竟是什么?
DeepSeek是一家位于杭州的人工智能初創(chuàng)公司,由幻方量化聯(lián)合創(chuàng)始人梁文峰于2023年7月創(chuàng)立,專注于大語言模型的研發(fā)。
在春節(jié)前,DeepSeek相繼發(fā)布了兩款同名的開源大語言模型:DeepSeek-V3(2024年12月26日)和DeepSeek-R1(2025年1月20日)。它們的性能可以與OpenAI的閉源模型GPT-4o和o1等其它大語言模型相媲美,且成本明顯低于其它模型。
DeepSeek-V3模型旨在提供高性價(jià)比的服務(wù),能夠快速地響應(yīng)用戶的需求,滿足自然語言處理、問答翻譯、內(nèi)容生成等日常任務(wù)的需求。DeepSeek-R1模型專注于復(fù)雜的推理任務(wù),特別是在數(shù)學(xué)問題、代碼生成、邏輯推理等領(lǐng)域具有更強(qiáng)的能力,但響應(yīng)時(shí)間也相對(duì)較長(zhǎng)。
- DeepSeek為什么會(huì)受到如此大的關(guān)注?
DeepSeek-V3和DeepSeek-R1在春節(jié)前發(fā)布后,憑借其與OpenAI為首的頂尖大模型相當(dāng)?shù)男阅芤约暗土挠?xùn)練成本和推理費(fèi)用,迅速引發(fā)了全球的廣泛關(guān)注。DeepSeek的高性價(jià)比挑戰(zhàn)了美國(guó)大模型的壟斷地位,它的推出使得更多企業(yè)和用戶能夠以更低的價(jià)格體驗(yàn)到最先進(jìn)的AI成果。
DeepSeek開源了其技術(shù)細(xì)節(jié)和模型權(quán)重,使得更多人能夠利用其成果進(jìn)行創(chuàng)新和研發(fā)。與此同時(shí),DeepSeek還免費(fèi)開放了在線服務(wù),吸引了大量用戶體驗(yàn),形成了前所未有的熱潮。在DeepSeek-R1正式發(fā)布7天后,DeepSeek超越ChatGPT登上了AppStore免費(fèi)應(yīng)用下載排行榜的榜首。DeepSeek的成功標(biāo)志著中國(guó)在AI領(lǐng)域的重大進(jìn)展,提升了中國(guó)在全球AI技術(shù)競(jìng)爭(zhēng)中的地位。目前,多個(gè)企業(yè)和高校已經(jīng)開始自主部署DeepSeek模型,進(jìn)一步證明了它的廣泛應(yīng)用潛力。
- 它為什么能用這么低的成本、這么有限的算法實(shí)現(xiàn)這么強(qiáng)大的能力?是只在中文表達(dá)上強(qiáng)大,還是各種性能都還不錯(cuò)?
DeepSeek能夠以較低的訓(xùn)練成本實(shí)現(xiàn)強(qiáng)大的能力,主要得益于DeepSeek長(zhǎng)期以來在模型架構(gòu)和算法層面的持續(xù)創(chuàng)新。
具體來說,DeepSeek通過使用混合專家架構(gòu)(MoE)和多頭潛在注意力(MLA)等技術(shù)有效降低了推理成本。同時(shí),借助數(shù)據(jù)蒸餾、分布式訓(xùn)練優(yōu)化、以及硬件層面的精細(xì)調(diào)優(yōu),DeepSeek進(jìn)一步提升了資源利用率,從而降低了訓(xùn)練成本。多種創(chuàng)新的優(yōu)化技術(shù)的融合使得DeepSeek在僅擁有較低的訓(xùn)練和推理成本的同時(shí),能夠提供強(qiáng)大的性能。
在中文的理解和應(yīng)用方面,DeepSeek有著突出的表現(xiàn),它不僅能夠理解古文,創(chuàng)作詩詞,還能準(zhǔn)確掌握時(shí)下流行的網(wǎng)絡(luò)用語。而相比之下,ChatGPT的中文雖然語法通順,卻顯得較為生硬。不過,DeepSeek的強(qiáng)大能力并不僅限于中文表達(dá),在官方公布的多項(xiàng)標(biāo)準(zhǔn)評(píng)測(cè)中,DeepSeek在英文、百科知識(shí)、長(zhǎng)文本、代碼、數(shù)學(xué)能力等領(lǐng)域均達(dá)到了頂尖水平。
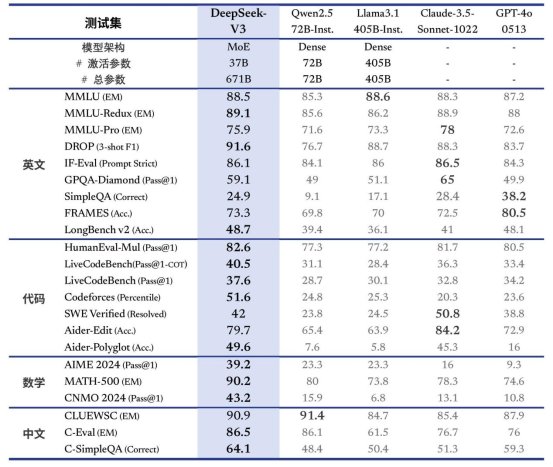
DeepSeek在不同領(lǐng)域的性能表現(xiàn)
(圖片來源:參考資料2)
- 在AI的范疇內(nèi),使用中文是否代表著更高的效率?
在AI領(lǐng)域,“效率”更高往往意味著處理速度更快,或者理解的準(zhǔn)確性更高,或者生成的內(nèi)容質(zhì)量更好。
首先,中文和英文在結(jié)構(gòu)上有很多不同。中文是表意文字,一個(gè)字可以表達(dá)很多意思,而英文是字母文字,每個(gè)單詞由多個(gè)字母組成。中文相比英文在表達(dá)上更簡(jiǎn)潔、高效,信息密度更高。在表達(dá)相同的意思時(shí),中文往往能更簡(jiǎn)潔地傳達(dá)內(nèi)容。因此在AI領(lǐng)域,使用中文可以提高表達(dá)效率,進(jìn)而降低成本。
但同時(shí),中文多樣的語義和復(fù)雜的語法結(jié)構(gòu)也對(duì)AI的理解能力提出了挑戰(zhàn)。比如,在中文中,“花”可以是植物,也可以是花費(fèi),這可能讓AI在理解上下文時(shí)更難。而英文雖然也有同義詞和多義詞的問題,但結(jié)構(gòu)上可能更清晰一些。所以,處理中文的時(shí)候,AI需要更多的上下文信息來準(zhǔn)確理解意思。
此外,數(shù)據(jù)量和模型的設(shè)計(jì)與優(yōu)化也應(yīng)當(dāng)納入考慮范圍。如果AI模型在訓(xùn)練時(shí)使用了大量的中文數(shù)據(jù),那么它可能在處理中文任務(wù)時(shí)表現(xiàn)更好。反過來,如果數(shù)據(jù)主要來自英文或者其他語言,那么AI在處理這些語言的時(shí)候效率可能會(huì)更高。某些模型可能是專門為某種語言而設(shè)計(jì)的,在這種情況下,在該語言上的效率自然就會(huì)更高。
關(guān)于中文在AI領(lǐng)域是否具有顯著的優(yōu)勢(shì),目前尚無定論,未來如何挖掘中文的潛在優(yōu)勢(shì)可能將成為重要的研究方向。
?
- 為什么在回答用戶問題的時(shí)候,DeepSeek可以展示其“深度思考過程”?
DeepSeek-R1在回答用戶問題時(shí)可以展示其深度思考過程是因?yàn)樗褂昧怂季S鏈(Chain of Thought, CoT)技術(shù)。思維鏈技術(shù)模仿人類的思考方式,它要求模型將復(fù)雜任務(wù)分解成簡(jiǎn)單步驟然后再逐步解決,從而增強(qiáng)模型在復(fù)雜推理任務(wù)中的能力。
OpenAI的o系列模型也使用了思維鏈技術(shù),但OpenAI并未向用戶公開模型的原始思維鏈,而是僅提供了一個(gè)思維鏈的總結(jié)。而DeepSeek-R1作為開源模型,則完全開放了思維鏈,用戶可以清晰地看到模型在解決問題時(shí)的全部推理過程。
?
- ChatGPT與DeepSeek分別有哪些特點(diǎn)?它們是否代表AI大模型以后的兩種發(fā)展方向,還是會(huì)融合發(fā)展?
ChatGPT基于OpenAI的GPT系列模型,使用了大量多語言數(shù)據(jù)進(jìn)行訓(xùn)練,支持多語言、多模態(tài),能夠跨語言和跨領(lǐng)域提供服務(wù)。作為閉源模型,它由OpenAI為用戶提供在線服務(wù)。
DeepSeek則在中文領(lǐng)域進(jìn)行了優(yōu)化,擁有較低的訓(xùn)練和推理成本。DeepSeek是開源模型,用戶可以根據(jù)需要自行部署并進(jìn)行定制化修改。目前它們的技術(shù)架構(gòu)和市場(chǎng)定位都有所不同,但隨著技術(shù)的發(fā)展,未來可能會(huì)出現(xiàn)更多相互借鑒融合的趨勢(shì),例如DeepSeek可能會(huì)借鑒ChatGPT的多模態(tài)能力,ChatGPT也可能會(huì)優(yōu)化其本地化服務(wù)以應(yīng)對(duì)DeepSeek等競(jìng)爭(zhēng)對(duì)手的挑戰(zhàn)。
?
- DeepSeek發(fā)布的是開源模型,開源以后,后面應(yīng)當(dāng)如何保持領(lǐng)先?
DeepSeek的創(chuàng)始人梁文鋒表示,現(xiàn)在的生成式人工智能并不是終點(diǎn),未來的目標(biāo)是朝著實(shí)現(xiàn)通用人工智能邁進(jìn)。在AI技術(shù)快速發(fā)展的當(dāng)下,大家都沒有碾壓對(duì)手的技術(shù)優(yōu)勢(shì),即使閉源也無法阻止被別人趕超。為了應(yīng)對(duì)這一挑戰(zhàn),他們希望將價(jià)值沉淀在團(tuán)隊(duì)的成長(zhǎng)之中,通過持續(xù)的創(chuàng)新來保持領(lǐng)先。開源的決策正是基于這一考量,開源可以打破技術(shù)壟斷,降低技術(shù)門檻,激發(fā)更廣泛的技術(shù)合作與創(chuàng)新。開源能夠吸引更多的開發(fā)者共同參與貢獻(xiàn),構(gòu)建一個(gè)開放與多元化的技術(shù)發(fā)展環(huán)境。DeepSeek希望通過這種方式推動(dòng)技術(shù)的長(zhǎng)遠(yuǎn)發(fā)展,保持領(lǐng)先地位,成為AI技術(shù)的引領(lǐng)者。
?
- 打開使用頁面,有“深度思考(R1)”和“聯(lián)網(wǎng)搜索”選項(xiàng),二者在使用上有何區(qū)別?如何能更好地使用這種推理型大模型?
打開深度思考(R1)選項(xiàng)后,后臺(tái)會(huì)切換到DeepSeek-R1模型,這個(gè)模型專注于需要復(fù)雜推理的場(chǎng)景,如數(shù)學(xué)或編程方面的問題。它能夠展示詳細(xì)的思維過程,提供推理步驟與最終結(jié)果。
聯(lián)網(wǎng)搜索選項(xiàng)則允許模型獲取實(shí)時(shí)互聯(lián)網(wǎng)搜索的結(jié)果,適用于時(shí)效性較強(qiáng)、需要獲取最新信息的問題,模型可以根據(jù)搜索結(jié)果提供實(shí)時(shí)更新的答案。
在使用深度思考(R1)功能時(shí),在提問中用戶無需額外引導(dǎo)模型進(jìn)行思考,只需要明確表達(dá)自己的需求,避免模糊不清的表述,以便模型更好地理解并提供準(zhǔn)確的答案。在深度思考模式下,除了模型的最終答案外,用戶還可以關(guān)注模型給出的思考過程,從而更好地掌握解決問題的詳細(xì)方法。
?
- 哪些領(lǐng)域的工作受到DeepSeek的可能沖擊最大,甚至能被取代?
DeepSeek等大語言模型可能會(huì)對(duì)那些依賴信息檢索、數(shù)據(jù)分析、重復(fù)性高且目標(biāo)明確的行業(yè)產(chǎn)生沖擊。例如內(nèi)容創(chuàng)作、數(shù)據(jù)處理、翻譯校對(duì)、人工客服、人力資源管理和財(cái)務(wù)審計(jì)等領(lǐng)域,可能會(huì)被自動(dòng)化的AI技術(shù)所替代。AI可以高效地完成用戶需求的任務(wù),從而減少對(duì)人工的依賴。
然而,對(duì)于一些需要?jiǎng)?chuàng)造性、情感智力和人際溝通的工作來說,人工的參與仍然不可或缺。在AI技術(shù)飛速發(fā)展的當(dāng)下,人們需要不斷提升這些難以被AI輕易替代的能力。這些能力可以幫助個(gè)人在職場(chǎng)中保持競(jìng)爭(zhēng)力,確保在未來的工作環(huán)境中,人與AI能實(shí)現(xiàn)更好的協(xié)作和互補(bǔ),共同推動(dòng)社會(huì)進(jìn)步。
?
- AI發(fā)展的速度怎么這么快?會(huì)越來越快嗎?
AI在過去幾年中迅速發(fā)展,這得益于多個(gè)因素的推動(dòng)。
首先,計(jì)算能力的大幅提升,尤其是GPU等硬件技術(shù)的發(fā)展,使得AI模型能夠處理更大規(guī)模的數(shù)據(jù),訓(xùn)練出更復(fù)雜的模型,從而提升了整體性能。
其次,互聯(lián)網(wǎng)技術(shù)的飛速發(fā)展為AI訓(xùn)練提供了豐富的數(shù)據(jù)庫。同時(shí),深度學(xué)習(xí)領(lǐng)域算法架構(gòu)的突破,也使得AI的能力不斷增強(qiáng)。近年來,科技公司和投資者紛紛看到了AI的潛力,并在資金和技術(shù)上給予了大力支持,這些因素共同促進(jìn)了AI技術(shù)的飛躍發(fā)展。
雖然許多專家認(rèn)為AI將在未來繼續(xù)快速發(fā)展,但是否能夠保持當(dāng)前的速度仍然存在不確定性。樂觀者認(rèn)為,AI的進(jìn)步將會(huì)呈現(xiàn)指數(shù)爆炸的趨勢(shì),隨著AI智能的增長(zhǎng),AI迭代的速度將會(huì)越來越快,最終完全超越人類。然而,算力和數(shù)據(jù)可能會(huì)成為制約AI技術(shù)發(fā)展的瓶頸,大型模型的訓(xùn)練需要越來越多的算力,而計(jì)算能力的發(fā)展目前已經(jīng)不足以完全滿足AI訓(xùn)練的需求。同時(shí),人類現(xiàn)有的數(shù)據(jù)在未來幾年內(nèi)可能會(huì)被耗盡。
未來AI技術(shù)如何突破算力和數(shù)據(jù)的瓶頸,繼續(xù)飛速發(fā)展,仍然需要全世界科研人員的共同努力。此外,AI可能引發(fā)的倫理、法律與社會(huì)問題也逐漸引起了人們的擔(dān)憂,一些科學(xué)家已經(jīng)呼吁暫停開發(fā)更強(qiáng)大的AI系統(tǒng),直至人們可以確保其安全性和可控性。
?
參考資料:
- https://en.wikipedia.org/wiki/DeepSeek
- https://api-docs.deepseek.com/zh-cn/news/news1226
- https://api-docs.deepseek.com/zh-cn/news/news250120
- Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., ... & Piao, Y. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.
- Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., ... & He, Y. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.